เนื่องจากงานที่รับผิดชอบ จะต้องมีการโอนย้ายข้อมูลจากฐานข้อมูลอื่นๆมายัง Oracle เป็นประจำ พบว่าการย้าย MySql มายัง Oracle นั้นสามารถทำได้ง่ายมาก (อาจเพราะเจ้าของเดียวกัน) โดยมีวิธีดังนี้
1. ดาวส์โหลดและติดตั้ง Oracle SQL Developer
2. ทำการเชื่อมต่อไปยังฐานข้อมูล Oracle ด้วย User system
3. สร้าง Oracle User สำหรับเก็บข้อมูลจาก MySql และกำหนดสิทธิให้เรียบร้อย
4. ดาวส์โหลดไฟล์ Third Party JDBC Driver สำหรับ My Sql
5. เปิดการใช้งาน Third Party JDBC Driver โดยไปที่ Tools > Preferences > Database > Third Party JDBC Drivers
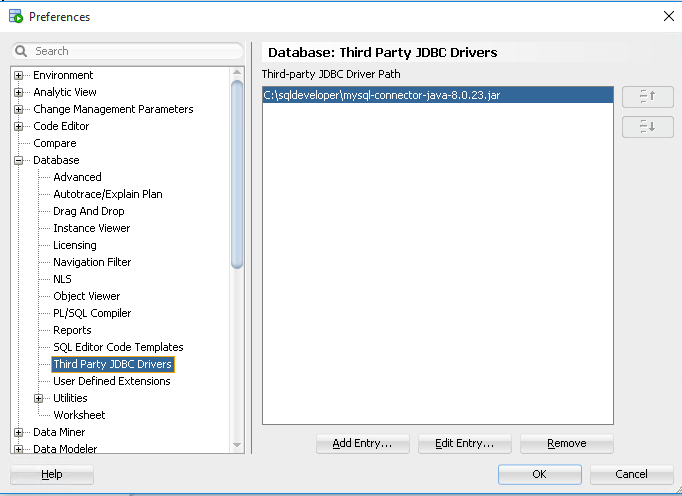
6. ทำการ Restart โปรแกรม Sql Developer เมื่อทำการ New Connection จะมีตัวเลือกเพื่อเชื่อมต่อไปยัง My Sql

7. ทำการเชื่อมต่อไปยัง My Sql หากต้องการเพียง Data, Schema สามารถคลิกขวาตารางที่ต้องการเลือก Copy To Oracle ได้เลย


เพียงเท่านี้ ข้อมูล Table, Field ก็จะถูกโอนย้ายและ Map Data Type ให้อัตโนมัติสามารถ Query จาก Oracle ได้เลย
แต่สำหรับงานที่ต้องการ Constraint, Trigger, ฯลฯ ด้วย จะมีขั้นตอนเพิ่มเติมดังนี้
- ไปที่ Tools > Migration > Migrate กำหนด User ที่จะใช้เป็น Migrate Repository (เก็บข้อมูลต่างๆขณะดำเนินการ Migrate)

2. กำหนดโฟลเดอร์จัดเก็บ Script, Log file

3. เลือก Connection My Sql ที่ต้องการ Migrate

4. เลือก My Sql User ที่ต้องการ Migrate

5. การ Map Data Type สามารถใช้ค่า Default ได้

6. เลือก Sql Object ที่ต้องการ

7. เลือก Connection ของ DB User ที่ใช้เก็บโครงสร้าง และคำสั่งต่างๆ ที่ระบบใช้ในการ Migrate

8. กำหนด User เป้าหมายที่จะนำข้อมูลเข้า จากนั้นเลือก Finish

เพียงเท่านี้ก็เรียบร้อยครับ ข้อควรระวังคือการเลือก Repository User ควรสร้างขึ้นมาใหม่ เนื่องจากจะมีการสร้าง Table ขึ้นมาระหว่างการ Migrate และการกำหนดสิทธิให้กับ User ต่างๆให้ครบถ้วน แบบที่สองดูเหมือนหลายขั้นตอน แต่ก็เป็นแบบ Wizard ที่ใช้งานได้ไม่ยาก หวังว่าบทความนี้จะเป็นประโยชน์ครับ























