OCR หรือ Optical Character Recognition จริง ๆ ก็มีใช้กันมานานมากแล้ว แต่การใช้งานก็จะผูกติดกับ Hardware พอสมควร แต่ในปัจจุบัน เราสามารถใช้ความรู้ด้าน Machine Learning / Deep Learning เพื่อให้คอมพิวเตอร์เข้าใจภาพได้ และสามารถนำมาประกอบกับเป็น Software สำหรับใช้งานของตนเองได้
ในบทความนี้ ทดลองใช้ Tesseract-OCR พี่พัฒนาโดย Google อ่านภาพ เอกสารที่ Print จาก Computer เป็นกระดาษ -> มีการเซ็นต์ชื่อ -> นำกลับมา Scan อีกครั้ง
*** มันเป็น Paperless ตรงไหน ? กฏหมาย Digital Signature ก็มีแล้วนะ ***
เอาเป็นว่า ดูผลงาน
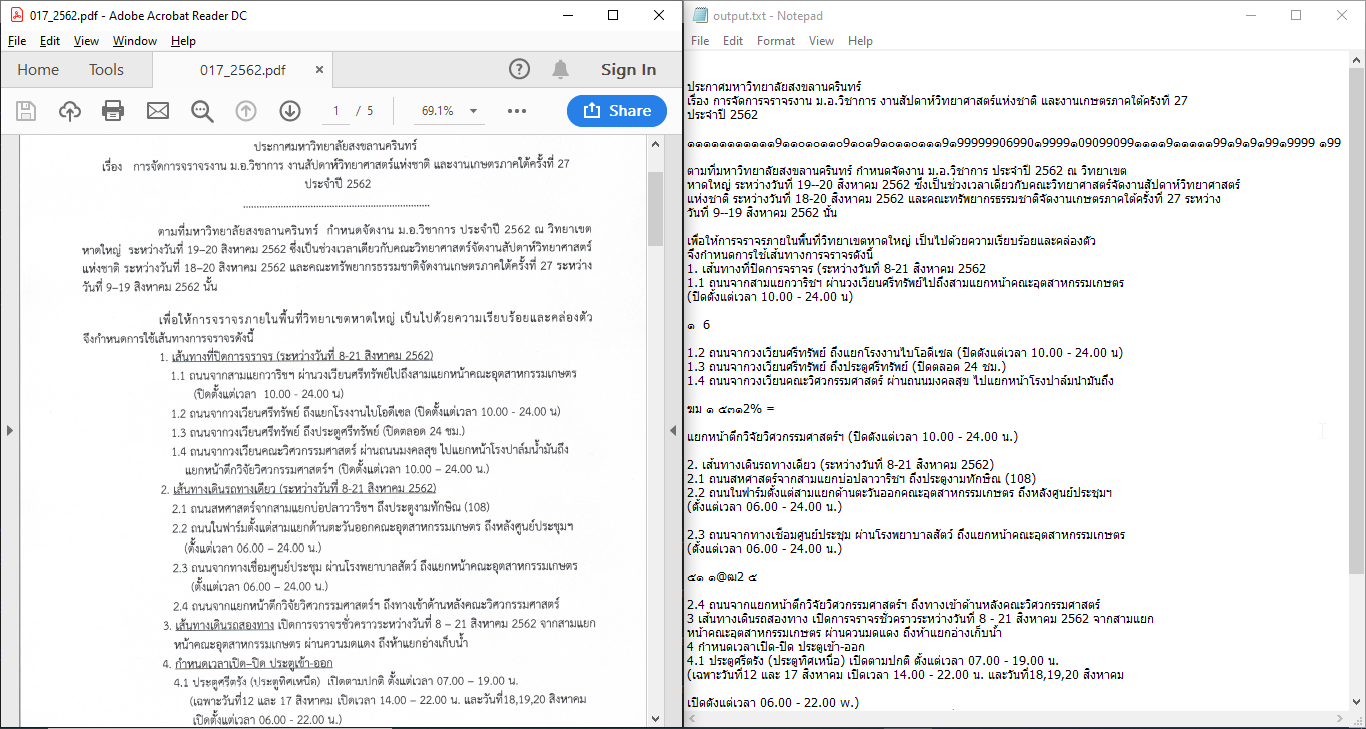
อ๊ะ บางคนบอกว่า เคยใช้แล้ว แต่ทำไมไม่ได้ผลอย่างนี้หล่ะ (โดยเฉพาะ ภาษาไทย) อิอิ มันมีรายละเอียดพอสมควร ไว้มีเวลาจะมาเล่าให้ฟัง
แต่แบบนี้ ต้องทำอะไรเพิ่มก่อน จึงจะอ่านได้

ผลก็พอจะอ่านได้ แต่ต้องทำอะไรเพิ่มก่อนจะให้ OCR อ่าน –> อันนี้คือยังไม่ทำอะไรเพิ่ม

มันไม่มีคำว่า “ก็ง่าย ๆ” หรอก หึ หึ หึ
Leave a Reply