ต่อจาก python #06 – Sentiment Analysis ด้วย Keras + Tensorflow เนื่องจากเรา Train โมเดล ด้วย ประโยคเพียง 9 ประโยค ซึ่งประกอบด้วยคำ 19 คำ เมื่อถูกทดสอบด้วยคำที่ “ไม่เคยเจอมาก่อน” ก็จะไม่สามารถวิเคราะห์ได้ถูกต้องนัก ยิ่ง ถ้าเจอกับประโยคที่ ไม่มีคำที่เคยเจออยู่เลย ก็จะได้ Zero Vector ไปเลย (ในทางเทคนิค สามารถตั้งค่าห้ Unknown Word มี Index = 1 ได้)

แก้ไขอย่างไร ?
ตอนนี้ เปรียบเหมือนโมเดลเป็นเด็กเล็ก รู้จักคำแค่ 19 คำ พอมีคำใหม่ ๆ มาก็จะไม่เข้าใจ วิธีการคือ ต้องสอนคำใหม่ ๆ และรูปแบบประโยคใหม่ ๆ ให้เค้า … แล้วจะหามาจากไหนหล่ะ ??
IMDB Movie reviews sentiment classification
เป็น Dataset การรีวิวภาพยนต์ 25,000 รายการ มี Label เป็น Positive/Negative รายละเอียดตามนี้
https://keras.io/datasets/#imdb-movie-reviews-sentiment-classification
เริ่มต้นใช้งาน
ทำตามตัวอย่างของ Keras ซึ่งมีข้อสังเกตว่า oov_char หรือ เมื่อเจอคำที่ไม่เคยรู้จักมากก่อน (Out-Of-Vocab) จะแทนค่าด้วย 2 และ index_from เริ่มจาก 3 (0,1 จะไม่ใช้ ส่วน 2 แทนคำที่ไม่รู้จัก ดังนั้น index แรกของคำที่ใช้คือ 3) จะเป็นคำที่พบ “มากที่สุด” ไล่ตามลำดับไป (ยิ่งตัวเลข index มาก ยิ่งมีการใช้น้อย)

สำรวจข้อมูล
พบว่า ถ้าเอาคำทั้งหมดจากรีวิวทั้งหมดมา จะมีคำทั้งหมด 88,584 คำ และ ประโยคที่มีความยาวสูงสุดคือ 2,494 คำ
Idea of Reverse IMDB word index Source: Source: https://jamesmccaffrey.wordpress.com/2018/04/27/inspecting-the-imdb-dataset-reverse-mapping-the-index-values/imdb_review_index_to_words/

แล้ว ส่วนใหญ่รีวิวจะมีความยาวกี่คำ ?
Idea จาก http://www.awesomestats.in/python-dl-imdb-classification-1/
ถ้าเอา ค่า Mean + 2 SD ก็จะพบว่า ความยาวประมาณ 591 คำ

ข้อมูลจะอยู่ในรูป Sequence หรือ Vector of Integer แล้ว

ต่อไป ก็ Pad ข้อมูล และ Truncate ให้อยู่ในความยาวที่กำหนด (ในที่นี้คือ most_sentence_len = 591)

ข้อมูลหน้าตาประมาณนี้

แบบที่ 1 ใช้ข้อมูลทั้งหมด
ทดลองใช้ คำทั้งหมดในจากข้อมูล IMDB (88,584 คำ) และ ใช้ความยาวประโยค 591 คำ

ผลที่ได้ ไม่ค่อยดี

แบบที่ 2
กำหนดให้ Vocab ที่รู้จัก เป็น 500 คำแรกที่ใช้มากที่สุด และกำหนดความยาวประโยคสูงสุด 100 คำ


ผลที่ได้ ดูดีขึ้น
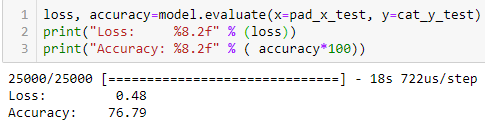
(สังเกต Param ใน Embedding Layer = 16,000 และ เวลที่ใช้ต่อ Epoch ประมาณ 60-70 วินาที)

วัด Accuracy ตอน Train ได้ 76.86% โดย Test Dataset ประมาณ 76.79% ก็ถือว่า พอดี
แบบที่ 3
กำหนดให้ Vocab ที่รู้จัก เป็น 50,000 คำแรกที่ใช้มากที่สุด และกำหนดความยาวประโยคสูงสุด 100 คำ


ผลที่ได้ ดูดีขึ้น
(สังเกต Param ใน Embedding Layer = 1,600,000 และ เวลที่ใช้ต่อ Epoch ประมาณ 80 วินาที)

ตอน Train ได้ Accuracy ถึง 94.46% แต่ ตอน Test แต่แค่ 78.12% อย่างนี้เรียกว่า “Overfit”

สรุปคร่าว ๆ
จะเห็นได้ว่า การสร้าง Deep Neural Network ด้วย Keras นั้น ไม่ยาก แต่การปรับค่า Hyper parameter ต่าง ๆ นี่แหล่ะ เป็นศิลปะ
หวังว่าจะเป็นประโยชน์ครับ





