บทความนี้กล่าวแบบทางเทคนิค ไม่เน้นวิชาการ ทฤษฏีมากนัก
Sentiment Analysis เป็นตัวอย่างที่ดีของการเริ่มต้นทำงานด้าน NLP (Natural Language Processing) เริ่มจากหาตัวอย่างประโยค (Inputs) และเป้าหมาย (Labels) แยกคำจากประโยค (Tokenization) แปลงให้เป็นตัวเลข (Word Representation) แล้วสอน NN (Train) วัดผล (Test/Evaluate) แล้วนำไปใช้ โดยป้อนประโยคเข้าไป แล้วดูว่า โมเดลของเราจะจัดให้เป็น Labels ใด (ในตัวอย่างนี้จะเป็น Multiclass (Multinomial) Classification)
ดู Jupyter Notebook
Input
สมมุติเรามีตัวอย่างประโยคประมาณนี้
แบ่งเป็น Positive, Neutral, Negative เพื่อไว้ใส่เพิ่มเติมได้ แล้วเอามารวมกันเป็น data โดยแปลงเป็น Numpy Array เพื่อสะดวกในการ Tokenization ต่อไป

Tokenization
ใน Keras มีเครื่องมือให้แล้ว คือ Tokenizer ใน Keras Text Preprocessing fit_on_texts ทำหน้าที่ แปลงข้อมูล “หลาย ๆ ประโยค” จาก data ในคอลัมน์ 0 ให้เป็นคำ ๆ โดยแยกคำด้วย “เว้นวรรค” และกำหนด Index ให้แต่ละคำ (word_index) โดย “เรียงตามความถี่” จะสังเกตุว่า คำว่า i , it อยู่อันดับ 1, 2 ตามลำดับ (และจะเห็นว่า มีการแปลงเป็น lower ทั้งหมด)

One-hot Encode สำหรับค่า labels
keras มี to_categorical method ทำหน้าที่เปลี่ยน Integer เป็น One-hot Encode ดังตัวอย่างด้านล่าง ในการแปลงกลับ ใช้ argmax method ของ Numpy

เตรียมประโยค ให้เป็น Sequence ที่มีความยาวเท่ากัน
การนำข้อมูลเข้าสู่ NN ต้องเตรียม Array ที่มีขนาดเท่า ๆ กัน ดังตัวอย่าง
ในที่นี้ใช้ texts_to_sequences แปลง ประโยค ให้เป็น Sequence (Array of Integer)
จากนั้น หาความยาวของประโยค และหาค่าสูงสูด (maxlen) — มีทั้งข้อดีข้อเสีย
แล้ว เติมเต็ม (Padding) ให้ทุกประโยค มีความยาวเท่ากัน โดยเติม 0 ข้างท้าย (padding=’post’)

Word Embeding
Word Embedding เป็น “หนึ่งในหลายวิธี” ของการแปลง คำ เป็น เวคเตอร์ของจำนวนจริง (vector of real number) จะเห็นได้ว่าตัวแปร x ข้างต้น เป็นจำนวนเต็ม (Integer) มีมิติเดียว ส่วน Word Embedding จะแปลง คำ ๆ นี้ (แทนด้วย) เป็นเวคเตอร์หลายมิติตามต้องการ (output_dim) โดยคำนวนจาก input_dim=จำนวนคำทั้งหมด (vocab_size) และ input_length=ความยาวของประโยคสูงสุด (maxlen)
ตัวอย่างต่อไปนี้ แปลง x จำนวน 9 ประโยค เป็น Word Embedding ซึ่งกำหนด input_dim=vocab_size, input_length=maxlen (ในที่นี้คือ 6) และ ต้องการแสดง Word Embedding เป็น Vector 2 มิติ (output_dim=2)

จะเห็นได้ว่า ผลจาก Word Embedding จะได้ Array ขนาด 9 x 6 x 2 นั่นคือ ได้ เวคเตอร์ของแต่ละคำมี 2 มิติ แต่ละประโยคมี 6 คำ และ มีทั้งหมด 9 ประโยค (ตัวอย่างข้างต้น แสดงตัวอย่างแรก คือ จาก [ 1 8 2 0 0 0] )
ถ้าลองเปลี่ยน output_dim = 16 จะได้ผลดังนี้

วิธีการนี้ ทำให้สามารถคำนวณว่า คำใด มีความสัมพันธ์กันขนาดใดได้ เช่น king – man + woman = ?? ซึ่งมนุษย์เราจะตอบว่า queen เป็นต้น
 Source: https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12
Source: https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12
ลองใช้ Flattern และ Dense
จาก python #03 – Train/Validation/Test and Accuracy Assessment with Confusion Matrix ได้กล่าวถึง Layer แบบ Fully-Connected หรือที่เรียกว่า Dense มาแล้ว ตอนนี้จะเอามาต่อกับ Embedding Layer แต่ เนื่องจาก Dimension ที่ออกจาก Embedding Layer เป็นแบบ 3D จึงต้องนำมาแผ่ หรือที่เรียกว่า Flattern ก่อน

ผลที่ได้คือ

ซึ่ง … ดูไม่ดีเลย
LSTM – Long Short-Term Memory
ในการทำงานด้าน NLP มี Layer อีกประเภทที่เรียกว่า Recurrent Neural Network (RNN) ซึ่งเหมาะสำหรับงานที่มีลำดับเวลา เช่น ประโยคคำพูดเป็นต้น แต่ RNN พื้นฐานมีปัญหากับการ Train ข้อมูลที่มีความยาวมาก ๆ จึงมีการพัฒนา LSTM และ GRU ขึ้นมา (ขอข้ามรายละเอียด) ต่อไป จะลองนำ LSTM มาแทน Flattern และ Dense

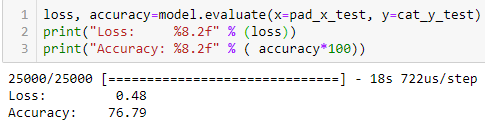
ผลที่ได้คือ

ดูดีทีเดียว !!!
ทดสอบการใช้งาน
สร้างข้อมูลทดสอบ โดยประกอบไปด้วย คำที่โมเดลเคยเจอ และคำที่ไม่อยู่ใน Dictionary ซึ่งจะถูกแทนด้วย 0 ตามนี้

ผลที่ได้คือ

สวยงาม พอรับได้
หวังว่าจะเป็นประโยชน์ครับ