เนื่องจากระบบสืบค้นที่ดูแลอยู่เจอปัญหาค้นหาเลขไทย “๑ ๒ ๓ …” ไม่เจอ หลังจากตรวจสอบจนแน่ใจแล้วว่าก่อนจะส่งคำสั่ง Query ไปยังฐานข้อมูลไม่ได้เผลอตัดเลขไทยออกที่ขั้นตอนไหน จึงทำการตรวจสอบคำสั่งที่ใช้ในการค้นหา พบว่าใช้ฟังก์ชัน
SELECT * FROM THAI_LIBRARY WHERE CONTAINS(BOOK_NAME, '๑๐๐ ปีชาติไทย', 1) > 0;
จากคำสั่ง (ที่สมมุติขึ้น) ด้านบนจะเห็นได้ว่าใช้ CONTAINS ซึ่งเป็นฟังก์ชันที่อยู่ในกลุ่ม Oracle Text ซึ่งฟังก์ชันนี้จะค้นหาคำใกล้เคียงจาก Index แล้วคืนค่า Score มาให้เราเพื่อใช้เป็นเงื่อนไขพิจารณาว่าจะใช้ข้อมูลรายการนั้นหรือไม่
{kind=link}
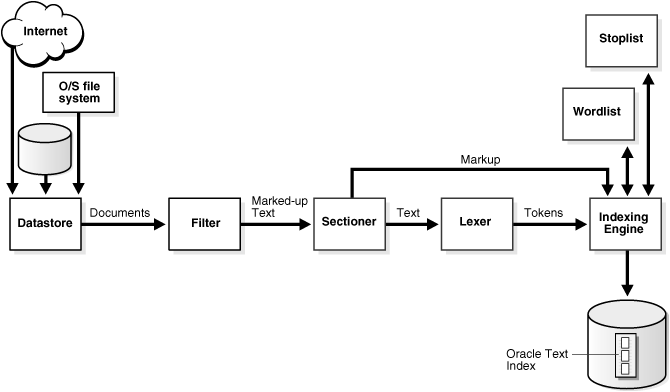
ภาพด้านบนแสดงขั้นตอนการสร้าง Oracle Text Index เนื่องจากระบบจัดเก็บข้อมูลเป็น Text อยู่แล้วจึงไม่มีการกำหนด Fillter, Sectioner ทำให้จุดที่ต้องตรวจสอบว่า เลขไทยเราหายไปจาก Index ได้ยังไงเหลืออยู่คือ Lexer ที่จะเป็นตัวกำหนด Wordlist, Stoplist ในการทำ Index ต่อไป ไปดูว่ามี Lexer อะไรบ้าง
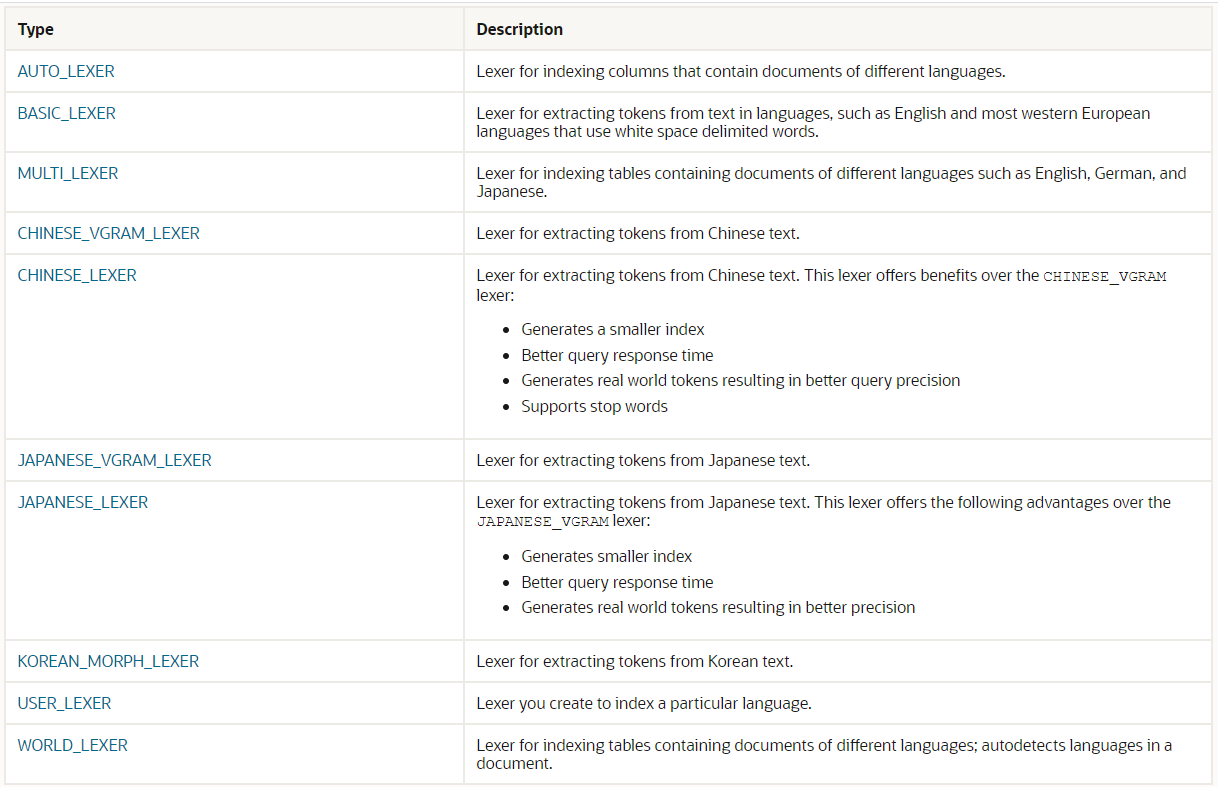
จากตารางด้านบน เนื่องจากฐานข้อมูลของระบบที่ดูแลอยู่ประกอบไปด้วย ภาษาไทย ภาษาอังกฤษ เป็นหลัก และอาจจะมีภาษาอื่นๆปนอยู่ด้วย Lexer ที่น่าจะใช้ได้คือ AUTO_LEXER, MULTI_LEXER, WORLD_LEXER หลังจากได้ทดสอบกำหนดค่า Lexer ให้กับฐานข้อมูล และทดสอบค้นหาด้วย เลขไทย พบว่าจะต้องใช้ WORLD_LEXER จึงจะสามารถรองรับกรณีนี้ได้ โดยใช้คำสั่งดังนี้
EXEC CTX_DDL.CREATE_PREFERENCE('WorldLex', 'world_lexer');
DROP INDEX USER01.IDXFT_THAI_LIBRARY_BOOKNAME;
CREATE INDEX USER01.IDXFT_THAI_LIBRARY_BOOKNAME ON USER01.THAI_LIBRARY(BOOK_NAME)
INDEXTYPE IS CTXSYS.CONTEXT
PARAMETERS('LEXER WorldLex STOPLIST CTXSYS.EMPTY_STOPLIST SYNC(ON COMMIT)')
NOPARALLEL;
USER01 คือ User ของฐานข้อมูล Oracle
THAI_LIBRARY คือ ชื่อตาราง
BOOK_NAME คือ ชื่อคอลัมภ์ ที่ต้องการทำ Index
IDXFT_THAI_LIBRARY_BOOKNAME ชื่อ ตาราง index
ผลพลอยได้ จากการปรับในครั้งนี้พบว่าเดิมต้องทำการตัดคำให้เรียบร้อย (เนื่องจากค่า Default คือ Basic Lexer ที่แบ่งคำด้วยช่องว่างเท่านั้น) เพื่อค้นหา แต่เมื่อปรับ Lexer ให้ถูกต้องสามารถส่งคำค้นเป็นประโยคยาวๆ ไปค้นหาได้เลย หวังว่าบทความนี้จะเป็นประโยชน์กับท่านที่ใช้งาน Full Text Search ของ Oracle และประสบปัญหาคล้ายๆกันนี้ครับ
Leave a Reply