สวัสดีครับ
บทความนี้เขียนเพื่อนำเสนอ Features ใหม่ บนภาษา C# 7.0 พร้อมกับเปรียบเทียบกับเวอร์ชั่นก่อนหน้าครับ ซึ่งเพิ่งจะ Release ออกมาเมื่อวันอังคารที่ 7 มีนาคมที่ผ่านมานี่เอง และได้เป็นส่วนหนึ่งของ Visual Studio 2017 ไปเรียบร้อยแล้วครับ (มีให้ดาวน์โหลดใน Microsoft Imagine แล้วครับ ซึ่งขณะเขียนบทความนี้เป็นเวอร์ชั่น Release Candidate (RC))

ขั้นตอนการติดตั้ง ไม่ขอเอ่ยถึงนะครับ เชื่อว่าทุกคนติดตั้งเป็น ส่วนสำคัญจะเป็นการเลือก Component สำหรับติดตั้งครับ เลือกตามที่ต้องการ ซึ่งใน Microsoft Imagine จะเป็น Professional Edition ครับ เพียงพอสำหรับการใช้งาน

ตัวอย่าง Source Code สามารถ ดาวน์โหลดได้ที่นี่ ครับ
เริ่มกันเลยครับ
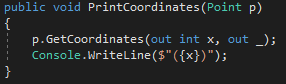
ก่อนหน้าตัวแปร out variable จะต้องทำการประกาศค่า (pre-declare) ก่อนที่จะนำไปใช้

แต่ด้วย C# 7.0 สามารถ declare ค่าพร้อมกับรับค่าจากส่วน out argument ได้ทันที

ตัวอย่างการนำไปใช้งาน กับ Decision if…else…

ซึ่งหากเราต้องการ discards ค่าตัวแปรที่รับมา ก็สามารถทำได้ ด้วยการใส่ “_”

เป็นการตรวจสอบว่า element ที่มีอยู่นั้นมีรูปร่าง (shape) หรือค่า (value) ตรงกับที่ต้องการหรือไม่ ดังตัวอย่าง
Is expression

ตัวอย่างการนำไปใช้งานร่วมกับการ decision if…else… ร่วมกับ method Try…

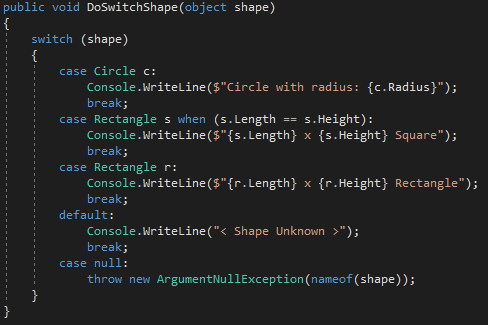
Switch expression
สามารถ switch โดยใช้ type ได้ (ไม่เฉพาะ primitive types) ซึ่งสามารถนำ patterns มาใช้ในส่วนของ case และสามารถเพิ่มเงื่อนไข (condition) ได้ ดังตัวอย่าง

คือการ return ค่าจาก method มากกว่า 1 ค่า (ในเวอร์ชั่นก่อนหน้าของ c# ก็สามารถทำได้ โดยใช้ out parameters หรือ System.Tuple<…> หรือสร้าง transport type ด้วยตัวเอง (custom-built) หรือให้ return ค่าเป็น anonymous type ผ่าน dynamic return type) ซึ่งในเวอร์ชั่นใหม่นี้ ไม่จำเป็นต้องทำเช่นนั้นอีกแล้ว ดังตัวอย่าง

(กรณี target framework ต่ำกว่า 4.6.2 จะไม่สามารถใช้ได้ ให้เลือก target framework ของ project เป็น 4.6.2 หรือไม่ก็ค้นหา “System.ValueTuple” จาก Nuget Package ครับ
การนำไปใช้งาน หรือเรียกจาก method อื่น สามารถรับค่า tuple ผ่านประเภทตัวแปร var โดยสามารถเข้าถึงแต่ละ element แบบ individually ได้เลย

ซึ่งถ้าสังเกตตอน coding พิมพ์ตัวแปร names จะขึ้น Intellisense Item… ให้เลือก

หรือจะตั้งชื่อให้กับ tuple เพื่อความสะดวกในการเรียกใช้งาน ดังตัวอย่างนี้ครับ

และแน่นอนว่า Intellisense ก็จะมีชื่อให้เลือก แทนที่จะเป็น Item1, Item2, Item3 ตามตัวอย่างก่อนหน้าครับ

เป็นอีกวิธีหนึ่งของการใช้งาน tuple คือการ deconstruct ซึ่งมี syntax สำหรับ split tuple value ใส่ในตัวแปลแต่ละตัว (individually variable)
ทั้งสามตัวอย่างด้านล่างนี้คือการนำค่ามาใส่ในตัวแปรที่ถูกสร้างขึ้นใหม่

ตัวอย่างข้างล่างนี้ คือการนำค่ามาใส่ในตัวแปรที่มีค่าอยู่แล้ว (existing variable value)

และเราสามารถ discard ค่าที่เราไม่ต้องการได้ ด้วยสัญลักษณ์ “_” เหมือนกับตัวอย่างแรกๆ ที่เคยกล่าวไว้ก่อนหน้านี้

บางครั้งการเขียน method (function) ซ้อนเข้าไปด้านใน method (function) อีกทีหนึ่ง จะช่วยให้เขียนโปรแกรมได้ make sense มากขึ้น ดังตัวอย่าง

เช่น ตามตัวอย่าง เมื่อมีการเรียก CalcFibonacci(int x) จะเรียก method (function) ข้างในอีกครั้งหนึ่งที่ชื่อ DoFib และ return ค่าเป็นแบบ tuple โดยที่ patermeter จะใช้งานได้ใน scope ของ method (function) ของตัวเองเท่านั้น
จากตัวอย่างข้างบน method ที่ implement อยู่ภายใน จะทำการ execute เมื่อมีการเรียกใช้เท่านั้น (ไม่สามารถเรียกมาจาก outer method หรือจาก method อื่นๆ ได้)

จะสังเกตว่า การทำงานนี้คล้ายๆ กับการสร้าง private method แยกไว้อีก method นึง แต่การสร้างแยกไว้นั้น อาจจะมีข้อผิดพลาดในการเรียกใช้งานโดยไม่ตั้งใจ กรณีที่ชื่อ method คล้ายกัน โดยไม่ผ่าน argument checking/validating (คือตัวแปร source, filter) อาจทำให้เกิดการทำงานที่ผิดพลาดได้
นอกจากการปรับเพิ่มความสะดวกในการเขียนโปรแกรมมากขึ้นแล้ว ยังปรับปรุงเรื่องความสะดวกในการอ่านโค้ด โดยเฉพาะเมื่อมีการ assign ค่าตัวเลขลงในตัวแปร
จึงได้มีการใช้สัญลักษณ์ “_” เพื่อใช้เป็นตัวคั่น (digit separator) โดยไม่กระทบกับค่าที่ assign (ใช้เพื่อให้เราอ่านได้สะดวกขึ้นนั่นเอง) – (improve readability)

เป็นการส่งค่าผ่านการ reference (ไม่ใช่การส่ง value) เช่น reference address, reference location ของ array เป็นต้น
สิ่งนี้การเขียนโปรแกรมทั่วไปอาจจะไม่ค่อยได้ใช้เท่าไหร่ และในบางกรณีอาจส่งผลถึงเรื่องความปลอดภัย (เช่นการ modified ค่าใน memory ทำให้โปรแกรมทำงานผิดพลาด เป็นต้น) ดังตัวอย่าง

- Expression bodied members allowed
expression body ที่ไว้สำหรับเขียน method, properties ใน C# รุ่นก่อนหน้า เป็นปัญหามาก เพราะเขียนได้เฉพาะ method และ properties เท่านั้น
และใน C# 7.0 นี้ ได้เพิ่ม accessors, constructors และ finalizers ซึ่งสามารถเขียนลงในในส่วนของ expression body ได้แล้ว ดังตัวอย่าง

ใน C# 7.0 สามารถเขียน throw exception ได้แม้ไม่อยู่ใน method (ของเดิมต้องอยู่ใน method เท่านั้น) โดยสามารถเขียนใน expression body ที่เดียวกับ accessors, constructors และ finalizers ได้เลย ดังตัวอย่างด้านล่างนี้

สำหรับโค้ดตัวอย่างโปรแกรม สามารถ ดาวน์โหลดได้ที่นี่ ครับ
(มีตัวอย่างตามบทความนี้ ทุกตัวอย่าง – รันบน Visual Studio 2017 ครับ)
ขอบคุณครับ
อ้างอิง ต้นฉบับจาก https://blogs.msdn.microsoft.com/dotnet/2017/03/09/new-features-in-c-7-0/














































 โดยวันนี้ขอเสนอการแต่งภาพให้มีมิติ ไปดูกันเลยจร้า
โดยวันนี้ขอเสนอการแต่งภาพให้มีมิติ ไปดูกันเลยจร้า
















{kind=link}